Whitepaper
Project Activities and Accomplishments
The Tier I project focuses on development of workflows in three areas: (I) Procedural Model Development and Export, (II) Repository Development, and (III) 3D Web Visualization with integrated metadata and paradata.
I. Procedural Modeling
Because of their focus on complex decision making, rather than complex model geometry, procedural modeling workflows provide a useful testing grounds for the development of standards to facilitate data interoperability, dissemination, and reuse; however, standard workflows to export and import procedurally generated 3D models that bring with them the underlying metadata, paradata, and descriptive data do not yet exist. More broadly, data curation for 3D models is still limited and efficient web-based 3D visualization that allows scholars to draw up 3D models from a database and then create their own reconstructions that tracks meta- and paradata changes is still lacking.
Because procedural models can be quickly generated and are directly linked to metadata and information about modeling choices data (paradata), are often embedded in larger modeling and simulation workflows and may be interchangeable or provide points of comparison between different projects, they can become “robust research tools” for humanists (Saldana 2014). However, before we can take fuller advantage of these models, we need to create workflows to (1) import 3D procedural models into open-source databases and repositories and (2) design a web-based infrastructure to store, deliver, and visualize these models into interactive 3D environments.
While procedural modeling allows us to efficiently generate many versions of architectural models from different types of data, the process is still restricted because proprietary software is widely employed in the research communto generate the models and other scholars may not have access to reuse the 3D models that are being generated. However, this problem is not insurmountable if we create export and import workflows that actively link metadata and descriptive data to these models for widespread reuse by other scholars and the public. Currently, 3D models available online may include metadata such as date created or number of 3D points or polygons; however, they don’t usually “carry” with them the paradata about modeling choices and the models are not in a database or repository that directly links the 3D models to descriptive data that can be “carried” over to web-based 3D visualizations. While X3DOM (http://www.x3dom.org/) does provide capacity for embedding additional paradata into the models and may be ideal for archiving 3D data, many commonly used 3D visualization software tools are not compatible with X3DOM, or do not facilitate reading the paradata. Additionally, most cultural heritage practitioners and managers do not use the X3DOM format for 3D models, but rather they use the OBJ, PLY, or COLLADA (DAE) formats. Our research focuses on the OBJ and COLLADA formats because they can be directly exported from ESRI’s CityEngine--the 3D procedural modeling software employed in this project and other humanities projects (Dylla et al. 2010; Haegler et al. 2009; Muller et al. 2006; Piccoli 2015; Rissetto and Plessing 2013; Saldana and Johanson 2013; Saldana 2015).
CityEngine: Procedural Generation with Computer Generated Architecture (CGA)
ESRI’s CityEngine allows for rapid-prototyping of 3D cityscapes based on Geographic Information Systems (GIS) data and a programming language named Computer Generated Architecture (CGA) that provides a mechanism for defining characteristics and components of buildings, along with the potential for random variability (ESRI 2018a). Basically CGA shape grammar allows users to rapidly generate 3D models for individual buildings (objects) or scenes (multiple objects) and iteratively add detail based on a set of rules. We have made available a set of sample CGA files developed in the project.
Advantages and disadvantages of CGA
|
Advantages |
Disadvantages |
|
Quickly create one or many buildings given set of instructions Use structure attributes to allow manual customization Provides mechanism for reports like generated building's area, elevation percentages, etc (ESRI 2018c) 3D models can be easily exported to various file formats |
Proprietary and only used by CityEngine Steep learning curve Not applicable to trying to replicate existing structures in a literal sense |
To allow users to efficiently, easily, and properly (for standardization purposes) export 3D procedural models from CityEngine, we developed Workflow #1, which provides a Python script to export 3D procedurally-generated scenes from CityEngine. We selected Python because it is the dominant language in GIS applications, compatible with CityEngine, and it promotes standardization and interoperability with other systems
.
Initially, the OBJ file format was selected for testing export flows. OBJ is an open 3D image format that describes a three-dimensional object or objects including 3D coordinates, polygonal faces, referenced texture maps, and illumination parameters. OBJ was selected due to its wide acceptance in the cultural heritage community as a “standard” format, and because it is compatible with most major open source software packages and scripting routines. However, a key finding of our research is that while suitable for tracking single structures, OBJ does not support scene hierarchies, which are essential to procedural modelling applications; therefore, we turned to the COLLADA (DAE) format—an XML-based schema that enables data transfer data among 3D digital tools. However, the COLLADA formathas pros and cons. While it supports scene hierarchies--the main focus of the project, it evolves more rapidly than the OBJ format, meaning data stored as COLLADA are treated inconsistently by different software packages, and because of this rapid evolution it is less popular as an archival format. Thus, the simplicity of the OBJ structure has made it a de facto “standard” in archival-oriented applications; however, in applications that need to support rich metadata and paradata within a scene hierarchy, we have found that Collada is the most appropriate “standard”.
Workflow 1 Requirements
Workflow 1 provides users with a mechanism for exporting buildings and scenes containing groups of buildings generated in CityEngine in a format compatible with import into the KDA alpha-repository designed in this project. For the purposes of this project, an object refers to a single object such as a building or structure and a scene refers to more than one of those objects along with their spatial relationships and orientation to each other--preserving these spatial relationships and orientation in export and import into different software is a key challenge for 3D data in the humanities that we investigated. [Note: our terminology differs from the CityEngine definitions for "object" and "scene." ]
The KDA repository tracks the version history for both individual objects and scenes, so Workflow 1 must export not only files representing those two items, but also associated metadata and paradata for each. The workflow focuses on exporting these requisite files and metadata in an organized and reproducible manner. Below, we present the requirements we identified for workflows for single objects and scenes.
Workflow requirements for single objects:
|
Individual Object Workflow Requirements |
|
|
Geometry File |
Common, open source file format Texture information and image files Centered at 0,0,0 |
|
Metadata |
Geographical coordinates Creator Date created Etc |
|
Paradata |
Choices made in the object's creation User modified attributes |
Scenes are more complicated, as they contain information about multiple objects and the objects' relationships to each other. Initially, we investigated using a file that only contained relational information in it but not the objects themselves. This approach would consist of a shapefile (vector data storage format for geographic features) with footprints of structures with unique ids matching objects stored in the KDA repository, which would then be associated upon import programmatically. This idea was discarded because of the impracticality of this type of association in most 3D software applications, which do not support this behavior without customization and scripting. Instead, Workflow 1 exports all of the included objects in a single file, along with metadata. This means the scene file does not require the individual object exports to be constructed in a viewer or 3D application, as it carries representations of the 3D objects with it but rather can be stored in a repository and then served out to different 3D viewers rather than only a single platform.
|
Scene Workflow Requirements |
|
|
Geometry File |
Common, open source file format Texture information and image files Centered at 0,0,0 Ability to distinguish individual objects included in the scene |
|
Metadata |
Geographical coordinates Creator Date created Etc |
|
Paradata |
Scene paradata derived from object Choices made in creation of individual objects within the scene User modified attributes on objects within a scene |
Another requirement for Workflow 1 was to implement it in a manner that would minimize user error and encourage standardization. To fulfill these requirements, we created the workflow as a Python script run through CityEngine as an export option (ESRI 2018b). While some elements of the workflow can be accomplished by manually working through the CityEngine export wizard, it is far more labor intensive and would require manual creation of the metadata, paradata, and file system organization for an exported scene. The use of a Python script, though it requires users to add the script to their workflow for setup, ensures that the process and output are standardized across user experiences and setups, mitigates user error, and minimizes required repetition.
Development Strategy
The first step of developing Workflow 1 was to break the workflow into tasks and investigate how to best accommodate object and scene requirements for each task. Mirroring the goals of the project, the tasks were to export the following: geometry file, metadata, and paradata with a 3D procedural object or scene. To understand the inner workings of these tasks, we first (where possible) we performed manual experimentation using the CityEngine graphical user interface (GUI). After finalizing the process and export options, a Python script was written to automatically perform the required tasks (i.e., to ensure metadata, paradata, and attributes standardized and packaged) and subsequent export.
These three tasks, assigning and packaging the geometry files, metadata, and paradata, posed unique challenges for export from CityEngine into a format useful for the KDA repository.
Choosing a Geometry File Format
As noted [link], both OBJ and COLLADA formats were considered for the application, and COLLADA was selected. This choice was made because COLLADA tracks scene hierarchies and allows a user to represent the relationships between structures and their scenes, including the possibility to maintain individual identifiers for structures
To illustrate the differences in between the OBJ and COLLADA geometry files, consider the following cube, created in Blender (Blender 2018), represented both as an OBJ and COLLADA.

Figure One
A cube
OBJs only describe the geometry, i.e., vertices and faces, and require a "material" file or MTL to display textures and materials (Murray and Van Ryper 1996). In the cube example, the OBJ file is 38 lines. COLLADA, by comparison, is 198 lines long. However, COLLADA makes up for its lack of simplicity with its ability to capture more information about geometry, including textures, lighting, camera angles, and more (Barnes, Finch, and Sony Computer Entertainment Inc. 2008). The majority of these have been omitted in the COLLADA sample code, but even the description of the object itself is more detailed in COLLADA than an OBJ file. This additional information becomes useful for 3D data reuse, particularly in capturing modeling choices, tracking changes, and ultimately facilitating citability.
Generally, it is important to keep in mind that the difference in the size and complexity of these two file formats continues to diverge as the size and complexity of the 3D representations are increased.
In addition to supporting scene hierarchies correctly, we considered the structure of the export from CityEngine in the criteria of file format. CityEngine exports OBJ files grouped by material rather than by geometry collection, e.g. creates a file with all the roofs, all the walls, all the doors, on the basis of each polygon’s associated texture, and does not use sets of connected polygons to define entities. In Figure X, you can see how an OBJ created by exporting from CityEngine, reimported into CityEngine, has grouped together the roofs of the buildings. The OBJ export format is incompatible with the requirements for representing a scene, as each object needs to be distinct and selectable.
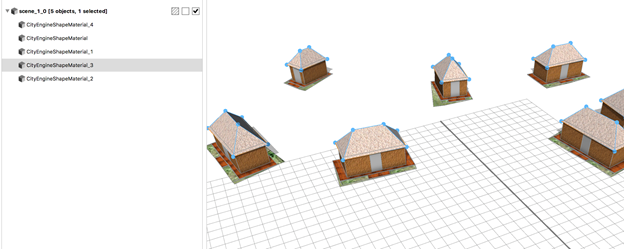
Figure Two
A Scene
CityEngine’s COLLADA export option "Create Shape Groups" supports export on the basis of connected groups of polygons, and is well suited to this project’s application.
Figure Three illustrates a clip of code from a COLLADA file with two objects named "building1" and "building2", whose geometries are described separately from each other. On export, CityEngine populates the node name (such as "building1") from its own "Name" field for each object. Therefore it is necessary that the user ensures that all top level nodes, representing structures, are correctly populated.
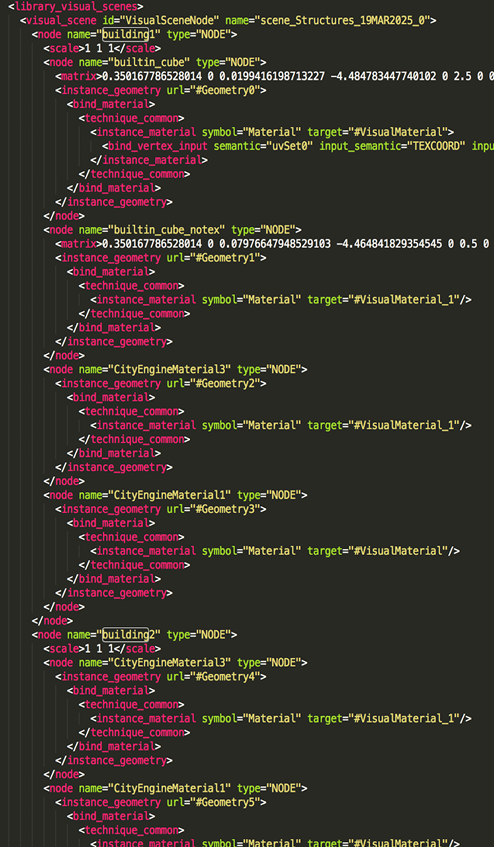
Figure Three
Code from COLLADA file
Another requirement of the geometry file export was to center the coordinates of the object on 0,0,0 to ensure that the 3D object or scene “plays” well with other 3D viewers. This criteria is critical if the 3D object or scene is georeferenced, i.e. has real-world coordinates. For example, an advantage of CityEngine is it can use shapefiles and associated attributes (e.g., height) to generate georeferenced 3D models; however, geolocation becomes a disadvantage when the model is outside of CityEngine because it often creates a problem for import into other 3D visualization software. While many 3D software do not handle georeferenced data, this is rapidly changing. We tested export options available in the CIty Engine GUI to determine how to center an object at 0,0,0, and then the same functionality was implemented in Python. However, importantly the Python export script we developed stores geolocation (i.e., real-world coordinates) as metadata for documentation and reuse purposes in CityEngine or other geospatial software.
The criteria for the geometry file including: capturing scene hierarchies, retaining texture information, and "zeroing" the coordinates of the file content were accomplished using the settings illustrated in Figure Four in the COLLADA wizard in CityEngine and as code in the Python Exporter in CityEngine:
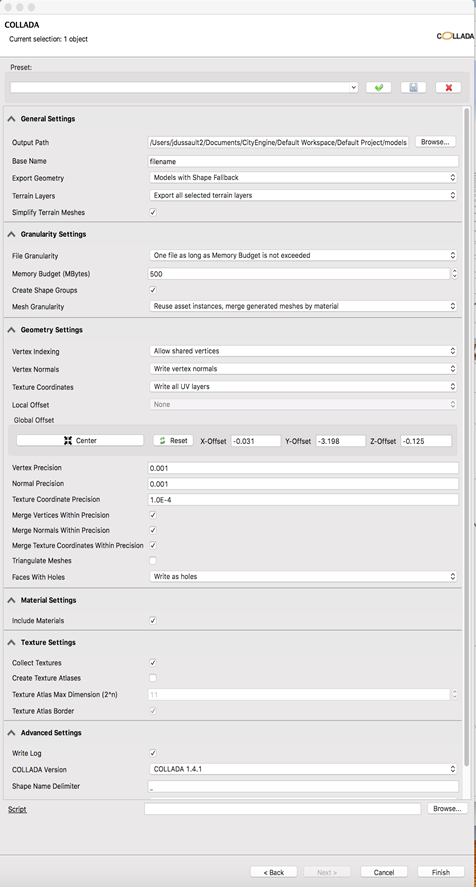
Figure Four
Screenshot of CityEngine
Metadata
Exporting metadata from CityEngine is relatively straightforward. Though it is possible to embed some metadata in COLLADA via the <contributor> and <comments> tags (Barnes, Finch, and Sony Computer Entertainment Inc. 2008), this project employs a "sidecar" metadata file in the form of JSON. The use of sidecar JSON allows the metadata to be easily parsed by software like the KDA repository, avoids potential problems with the <contributor> and <comments> sections of the COLLADA file not being retained by some mesh editing software, and makes the metadata human readable. This strategy also allows the use of a JSON metadata file in a standard way across various mesh formats, e.g. OBJ, COLLADA.
All of the metadata in the JSON file is programmatically obtained, minimising user error. Both objects and scenes have basic information like the date, software's label, and creator (obtained from the computer's current user account name).
|
Metadata Common to Object and Scene |
|
"collada_version" : "COLLADA_1_4_1", "creator" : os.getlogin(), "date" : datetime.datetime.now().strftime("%Y-%m-%d %H:%M"), "software" : ce.getVersionString() |
The scene JSON also includes a reference to the original coordinates of the scene, prior to being zeroed on export, along with the project system information. In this way, the original (georeferenced) location of a scene, before it was added to the KDA repository, may be retrieved. The export script does not include metadata about each object that appears in a scene, relying instead on the output of the file structure to relay the relationships. However, an object’s data structure could be included in future iterations of the system. Under this model, object specific metadata would be included within the scene sidecar JSON file.
Object level metadata potentially ingested into the JSON sidecar file include scene coordinate information (selection_centered) and per-object local coordinate information (shape_centered). Objects created with CGA rules will also have an associated rule file and start rule. Attributes associated with the shapefile from which an object was generated, manually added by a user, or programmatically generated by a CGA rule may also be ingested into the JSON sidecar file. Examples of these types of attributes range from an archaeological site name, to building height, textures, excavation status, architectural element specifications ("Portico Style: Hellenistic"), and beyond. These attributes are not normalizable and will not be functionally incorporated into the KDA repository, but could be saved and available to view. Handling these highly variable attributes presents some challenges. In future iterations of the KDA project, some attributes may be designated as standard, e.g. ‘site’, ‘responsible excavator’ and ingested programmatically. Other attributes must be manually added by the user on import into the KDA repository.
Paradata
Paradata, in this context, refers to the choices made when creating the objects and scenes. Conveniently, CityEngine's proprietary generation language, CGA, inherently describes these choices in the attributes, parameters, and comments stored in the code. There are two aspects to the paradata for each CityEngine model: the CGA and assets, and then modifications that a user makes to the CGA attributes. For example, the CGA applied to an object might say "choose a random texture from 'brick,' 'stone,' and 'marble,' " and point at three image files. Then, a user may decide that instead of the generated and randomly selected stone texture, they would prefer marble. That choice would not be captured by the CGA if another user was attempting to trace the creation of a particular object. "Methods to capture this level of paradata will be explored in future work.
The first type of paradata, the CGA and assets, are currently being downloaded by the Python export script as an RPK, or a rules package. This is a proprietary binary format that CityEngine reads. Figure Five illustrates an RPK file as seen in CityEngine.
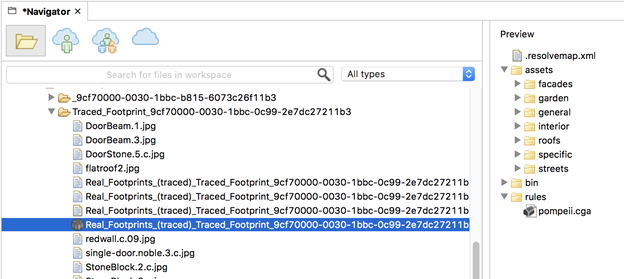
Figure Five
RPK File in CityEngine
The RPK captures all dependent CGA files and assets and conveniently packages them (ESRI 2018d). Because the format is proprietary and only readable in CityEngine, RPKs are not a sustainable solution for the KDA platform. To avoid use of the RPK, the CGA file must be parsed to find assets referenced and other CGA files called iteratively until no more CGA dependencies are found, and all discovered files exported to the package prepared for ingest into the KDA repository.
The RPK or a package of files generated by recursively capturing CGA and assets programmatically for an individual object will be on the order of 100 MB in size. In one test, we found that the exported COLLADA file was 57 KB, but the associated RPK was 71 MB. Planning for large paradata files is therefore essential.
Some difficulties were encountered when trying to export user-altered attributes because CityEngine does not make CGA generated attributes available through its Python environment unless the user has altered them. Once the user has altered an attribute created by the CGA, the attribute shows up in the list provided by CityEngine through `ce.getAttributeList(object)` and its value can be retrieved (CLau-esristaff 2018). Prior to the user making changes, CGA attributes are not returned by `ce.getAttributeList(object)`, although they could be potentially retrieved other ways, like parsing the rather verbose results of `ce.getRuleFileInfo(path) to try to find attributes defined through CGA. Currently, the export script grabs the values of all attributes in `ce.getAttributeList(object)` and therefore will record any CGA attributes that were altered by the user, and therefore relevant paradata, but does not record unchanged CGA defined attributes.
Conclusions and Questions
The process of developing Workflow 1 was not limited to simply creating a Python export script, but also to investigating how useful the product of this workflow is for storage and manipulation with the KDA repository and web tools. Many decisions were made specifically with that application in mind. For example, through developing Workflow 1, we concluded that OBJ files were not suited for storing scene level metadata and paradata, and so instead are using COLLADA geometry files. We chose a sidecar JSON metadata file instead of embedding information in the COLLADA in order to aid ingest and portability. We determined a directory structure that contains information about scenes and objects with their supporting materials. We also created an effective means of exporting a geometry file and a minimum amount of metadata with a script that is easy to install, considerably faster to use than manually exporting each object (even when considering the use of saved option presets), and organizes the resulting files. Beyond these initial steps, further development work should be undertaking to address the points listed below.
How should the paradata be represented?
This workflow is currently exporting paradata as an RPK file, a zipped package of CGA and asset files. This workflow relies entirely upon the accessibility of CityEngine, but the KDA project itself is agnostic about the origin of procedurally generated models. Tracking changes to objects and scenes is a central requirement of the KDA project, and so while a proprietary language such as CGA would allow a user familiar with the syntax to study choices made in an object's creation without CityEngine, an RPK would be unviewable without access to the software. Programming the script to gather CGA and asset files recursively, as discussed above, would address the issue of an inaccessible binary format.
However, changing the format will not reduce the potentially massive sizes of the paradata. There are a few options that could reduce this impact. First, if the asset files are not important (the selected assets presumably having been exported with the object), would be to only capture the CGA files themselves and not include all possible combinations of assets. Second, which could be used in conjunction with the first option, would be to store the paradata outside of the individual object subdirectories, and instead a pointer would be added to their metadata referring to the location of the paradata. In this way, if a rule was used to generate 100 buildings, instead of 100 paradata file collections, there would only be one. How this reference might be stored by Fedora is an unexplored question, but one which would be important to decrease the potential storage costs of uploading potentially dozens of models that share identical paradata.
Should metadata for individual objects be contained in scene metadata? Paradata?
Currently, the only thing relating scenes and objects is the file structure of the completed export. It may prove useful to include metadata from the objects that are members of the scene, and metadata on scene participation in the metadata for the objects. This information might be organized in a variety of ways, for example as a simple list of the object files in the scene metadata. The scene could contain all of the metadata for each of the objects.
Can a list of attributes be created that users are encouraged to include in objects and would it be useful?
After workflow 1 is completed, scenes and objects are ready to be imported into the KDA repository. During this step, users are asked to correct and add attributes to their items, such as author attribution, geographic location, subject, and more. Some of this information may already have been encoded as attributes on a shapefile, or after the object's generation in CityEngine. If a list of recommended attributes is compiled, the KDA import step could potentially parse the JSON sidecar file and pre-populate fields from attributes with the recommended names. This might be particularly useful when it comes to non-normalized fields like excavation site, but unless if the user was also using a standardized set of values, attributes like time period and geographic area might not be particularly usable.
II. Repository
One of the goals of the Keeping Data Alive grant is to design the infrastructure for a repository to ingest, host, deliver,and retrieve 3D models linked to metadata, paradata, and descriptive data that can be visualized and edited in an open source 3D visualization environment with changes tracked by the repository. Workflow #2 provides instructions to help set up the repository environment on your own development machine or server that will import the 3D procedural models using the export_to_kda.py script.
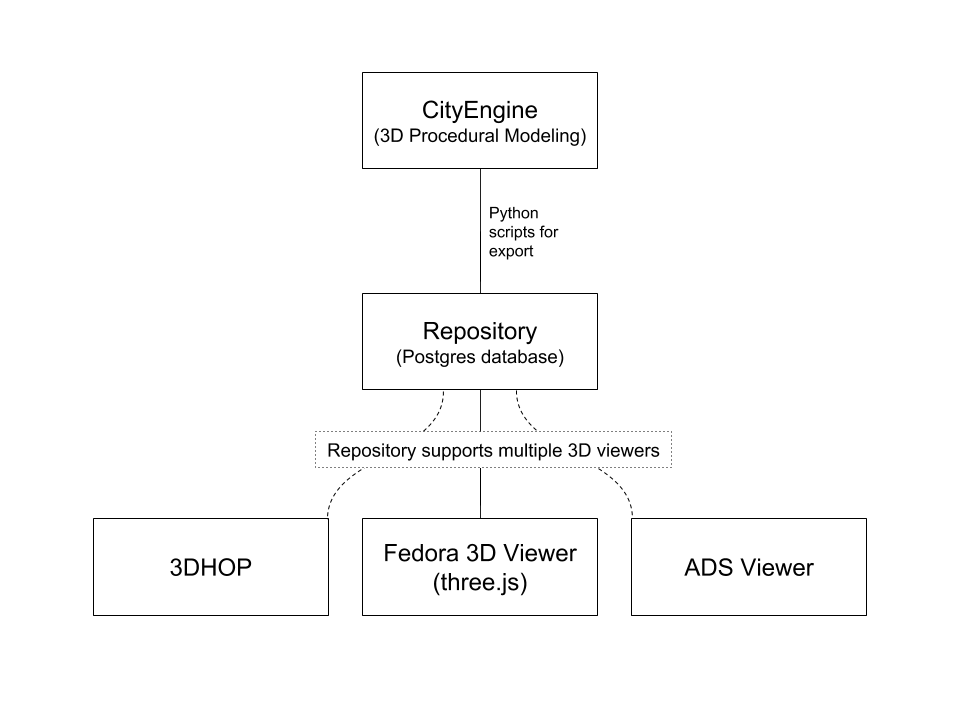
Figure Six
System Design Diagram
To make 3D models accessible and citable, a repository must exist that meets the following qualities:
- Enables deposit of 3D file types (.dae, .obj) in a manner that they can be called up, visualized, manipulated, and redeposited (i.e. not merely in a zipped file)
- Allow expandable and flexible metadata models with an emphasis on cultural heritage
- Allow linking of models, scenes, and versions of models and scenes
- Provide or enable RDF/machine readable metadata for interoperability with other systems
- Provide a system for assuring integrity of data deposited
- Provide a way to assign DOI's/permanent URL's to scenes and models
In the original project design, building infrastucture around the PostgreSQL-- a widely-used open source relational database; however, given that libraries are the main data stewards in the U.S. and given recent efforts preservation and access efforts by Community Standards for 3D Data Preservation (CS3DP) and the Library of Congress on Digital Stewardship of Intrinsic 3D Data, matching infrastructure commonly used in the libraries community was prioritized. We opted for a repository approach that can be customized, better meet libraries' requirements and potentially promote preservation and access efforts beyond individual projects. Along similar lines, building on existing capacity and infrastructure in the libraries community, the Research Description Framework (RDF) was selected because it offers a standard data structure for data interchange on the web,and is widely employed as a key component of linked data.
While any repository package that supports RDF for describing both metadata and structure and fulfills the above requirements, can be customized using the KDA infrastructure and scripts, we chose the Fedora repository package because of the substantial investment made by a broad community of users and developers. Additionally, we use the REST API web interface directly with the Fedora (Duraspace 2018) back end rather than other repository interface packages such as DSpace (Duraspace 2018) and Islandora CLAW (Islandora community 2018)because these interfaces restrict filetypes and complicate both metadata schema definition and resource identification in the Fedora back end. Importantly, this approach supports the inclusion of arbitrary metadata in RDF. The use of Fedora’s native API system is appropriate for initial development, and leaves the choices of repository interface for a production version open to future developer groups, who can employ compatible interface packages such as Samvera and Islandora. Fedora’s API further supports the creation of simple demos written in Python. (https://github.com/CDRH/keeping-data-alive/tree/master/fedora).
Metadata
While many digital humanities projects employ the Dublin Core metadata standard, the KDA team considered two other metadata models for the sample repository, CIDOC CRM (CIDOC Documentation Standards Working Group 2018) and the Europeana Data Model (EDM) (Europeana Foundation 2018, because these models are designed to describe cultural heritage materials. We selected EDM because it is flexible for many use cases and contains some of the properties of Dublin Core and CIDOC CRM, and primarily because it has support for describing relationships among Objects, Scenes, and Files--an essential requirement for this project. Moreover, EDM is a widely used metadata model, powering Europeana Collections (Europeana Foundation 2018), which contains over 58 million items. The broad and diverse user community suggests the format will be maintained and increases the compatibility of the metadata in the KDA system with related cultural heritage repositories.
In addition to Dublin Core and CIDOC CRM, the Europeana Data model contains elements from the Web Ontology Language (OWL), Friend of a Friend (FOAF), Simple Knowledge Organization System (SKOS) and a few metadata models. These inclusions are what makes the EDM such a powerful and flexible data model for cultural heritage objects. The EDM provides a detailed mapping guideline for applying metadata to cultural heritage materials, so we won’t reiterate those guidelines, except to clarify how we are using some elements to provide structure to our sample repository.
The KDA team required a method for expressing the relationships among objects, Scenes, and derivative Scenes that allows users to track the entire chain of creation. For instance, if a user creates a Scene, and another user modifies it and publishes the revised Scene, a Scene now has two creators. This chain of creation could continue infinitely, so a flexible metadata model is needed to take into account the complexity of the relationships, i.e. it needs to track changes to the Scene.
The following metadata is used to relate objects inside the repository and track versions (derivatives) of objects and Scenes to create a chain of attribution.
dcterms:hasPart and the inverse dcterms:isPartOf
- Used to relate scenes to individual models. For example, Scene A may contain models A, B, C, and D. Scene A will have "hasPart" connecting to models, and the models will have "isPartOf" connecting to scenes.
- Models will have a record indicating model level metadata (creator, description) and can also use "hasPart" to indicate files included in the model.
dcterms:hasFormat and dcterms:isFormatOf
- Many file formats exist for 3D models and yet they often have similar formats that contain, essentially, the same information. The "hasFormat" can be used to direct users to other file formats that are functionally the same. For example, the .obj and .dae formats of the same model may be linked to each other in this manner.
dcterms:requires and the inverse dcterms:isRequiredBy
- Some 3D models comprise multiple files that are required to work. For example, .obj files may have accompanying textures. In this case, the .obj file references an .mtl file to apply textures. By using requires and isRequiredBy, these fields can be linked together in a way that indicates these files go together, and could be used by an application to ensure that downloading one triggers the download of the other.
dcterms:hasVersion and the inverse dcterms:isVersionOf
- This metadata can be used to track versions of ojbects or Scenes, creating a chain of attribution. For example, if user A created model A and user B takes model A, changes it, and re-publishes it as Model A(1), the metadata hasVersion can record that this is a new object that has, essentially, two creators. This chain of attribution could occur infinitely. To be determined is how attribution might take this kind of versioning into account. It would become unwieldy to list every creator in a citation, but a permanent link to a resource containing this information would make it possible to look up all creators.
edm:isDerivativeOf
- Files that are automatically created as derivatives (for example, upon ingest or by script) could use isDerivativeOf to indicate provenance.
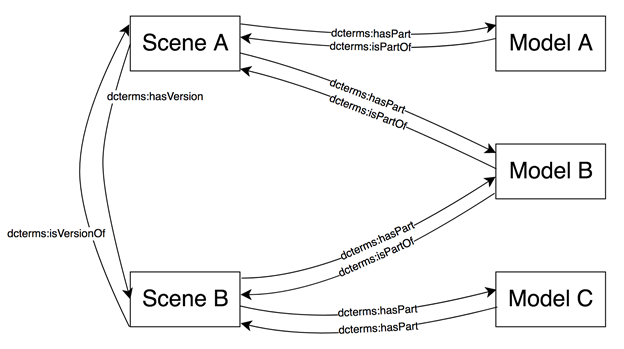
Figure Seven: Object (Model) to Scene Relations
Figure Seven depicts a scenario in which a user alters Scene A to include Model C instead of Model B, creating a new Scene, Scene B.The relationships are as follows:
- Scene A has Part Model A and Scene A has Part Model B
- Scene B has Part Model B and Scene B has Part Model C
- Scene A has Version Scene B
All of these relationships have an inverse, so model A is also Part Of Scene A, and Scene B is Version of Scene A.
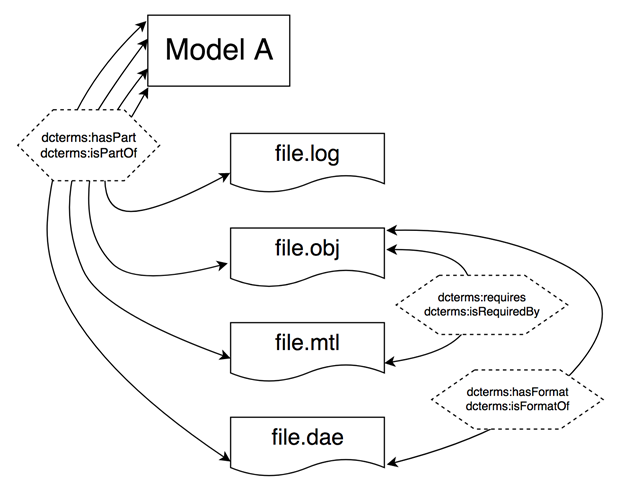
Figure Eight: Model to File Relations
Figure Eight depicts a subset of files that might be uploaded and associated with the object “Model A.” The relationships are as follows:
- Model A has part file.log (repeat for each filetype, .obj, .mtl, etc)
- file.obj requires file.mtl (if accompanying .mtl and texture files are present)
- file.obj has format file.dae (this indicated these formats are functionally similar)
These metadata have an inverse, file.log is part of Model A, file.mtl is required by .obj, and file.dae is format of file.obj
Limitations of software/process
While the approach we developed works to link derivations of objects and Scenes, robust implementation remains a challenge. A basic demonstration form, has been created for Scene ingest that demonstrates the tasks of linking versions of Ccenes and associating included objects. A shortcoming is that the potential for errors as a user manually inputs information on relationships. A better solution would be for an outside application (preferably an online application, but potentially a desktop application) to connect directly to the repository, read in an object or Scene, allow the user to swap objects and apply rules, and then publish the new version back to the repository. In this scenario, the application tracks the versions and parts of scenes and models, and correctly applies the correct links on publication. The repository would track the chain of users and edits, and would allow users to use, modify, and recombine models while preserving the metadata citing the original creators.
Overall, the ability to read and write from a repository should be as generalized as possible to allow for broad applicability and interoperability with 3D Viewers. Ideally, a repository would have a well-defined API that could be applied to other repositories, so software would not be locked into reading and writing from only one site.
III. 3D Web Visualization
Various 3D viewers exist to visualize and manipulate 3D models. While several desktop platforms [or software environments] exist to create and edit 3D models(e.g., Unity, meshlab, blender), there are fewer web-based 3D software platforms that support a full range of editing and annotation functions. Crucially, to the best of our knowledge, extant 3D web-based platforms to not support tracking of metadata and paradata. Thus, a main goal of the KDA project was to design customizable infrastructure (i.e., repository) and develop scripts to allow for users to interchange 3D models via an open source web-based viewer that tracks changes to geometry, metadata, and paradata. We developed Workflow #3 to export 3D procedural models from the KDA repository to an open source 3D viewer.
Proof of Concept Research
In Tier I, the KDA project developed a proof of concept to allow users to view and interact via an open source web-based 3D viewer with resources stored in a repository. We developed code in the form of a simple command line script to request resources from the repository and then designed a proof of concept to integrate that code into a prototype 3D web interface. The infrastructure employs the python scripting language with RDF capabilities and the three.js format to promote standardization and interoperability within the KDA system as well as outside of it.
Python Export Script: Repository to 3D Viewer
To maintain consistency and compatibility across the KDA infrastructure, Python--, the dominant language in GIS applications and language for CityEngine’s export routines--was also used for the interface between the repository and 3D viewer. Additionally, Python is compatible with many libraries that work with Fedora and many RDF resources.
RDFLib (RDFLib Team 2018a), a Python package, was selected to interface with the Fedora API because of its capabilities for requesting RDF resources from other servers, handling a variety of response RDF syntaxes including the Turtle syntax used by Fedora, and querying response RDF data. RDFLib is also well-documented with a variety of examples that cover simple and complex use cases.
We developed a command line Python script (Tunink 2018a) to test requesting data from the Fedora repository and filtering the response to select specific elements. The data are read from fedora using Turtle- Terse RDF Triple Language. A Turtle document is a textual representations of an RDF graph.
Sample Turtle format result read from Fedora
@prefix dc: <http://purl.org/dc/elements/1.1/> .
@prefix ebucore: <http://www.ebu.ch/metadata/ontologies/ebucore/ebucore#> .
@prefix fedora: <http://fedora.info/definitions/v4/repository#> .
@prefix fedoraconfig: <http://fedora.info/definitions/v4/config#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix ldp: <http://www.w3.org/ns/ldp#> .
@prefix pcdm: <http://pcdm.org/models#> .
@prefix premis: <http://www.loc.gov/premis/rdf/v1#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix test: <info:fedora/test/> .
@prefix xml: <http://www.w3.org/XML/1998/namespace> .
@prefix xs: <http://www.w3.org/2001/XMLSchema> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix xsi: <http://www.w3.org/2001/XMLSchema-instance> .
<http://cdrhdev1.unl.edu/fedora/rest/kda> a fedora:Container,
fedora:Resource,
ldp:Container,
ldp:RDFSource ;
fedora:created "2018-09-26T16:53:38.792000+00:00"^^xsd:dateTime ;
fedora:createdBy "bypassAdmin"^^xsd:string ;
fedora:hasParent <http://cdrhdev1.unl.edu/fedora/rest/> ;
fedora:lastModified "2018-10-11T22:34:53.356000+00:00"^^xsd:dateTime ;
fedora:lastModifiedBy "bypassAdmin"^^xsd:string ;
fedora:writable true ;
ldp:contains <http://cdrhdev1.unl.edu/fedora/rest/kda/11_temple_no_mesh_merge>,
<http://cdrhdev1.unl.edu/fedora/rest/kda/1_export_zeroed_import_zeroed>,
<http://cdrhdev1.unl.edu/fedora/rest/kda/Shapes%20Structures_19MAR2018>,
<http://cdrhdev1.unl.edu/fedora/rest/kda/stormtrooper>,
<http://cdrhdev1.unl.edu/fedora/rest/kda/tree>,
<http://cdrhdev1.unl.edu/fedora/rest/kda/type3_scene_dae> .
Digging into the KDA Repository
The KDA reposistory services link to storage services that store RDF resources as LDP (Linked Data Platform)containers. RDFLib provides multiple ways to filter an RDF graph (RDFLib Team 2018c) and includes a Resource class (RDFLib Team 2018d) for working with RDF resources. To browse these LDP containers, we added the ability to pass an argument, to the read_fedora.py script, for a LDP path to a resource within the repository. The script iterates through each tuple (i.e., a sequence of immutable python objects used to group together related data) within the RDF graph and directly matches for a selected predicate, for example, "ldp#contains" to return specific values from storage services (i.e., a PostgreSQL database underlying the Fedora repository.
THe Children (ldp#contains): http://cdrhdev1.unl.edu/fedora/rest/kda/stormtrooper http://cdrhdev1.unl.edu/fedora/rest/kda/type3_scene_dae http://cdrhdev1.unl.edu/fedora/rest/kda/tree http://cdrhdev1.unl.edu/fedora/rest/kda/1_export_zeroed_import_zeroed http://cdrhdev1.unl.edu/fedora/rest/kda/Shapes%20Structures_19MAR2018 http://cdrhdev1.unl.edu/fedora/rest/kda/11_temple_no_mesh_merge
If run without an argument, the script will request the root of the repository and print the container resources connected to the root resource as well as a short message about how to request them in subsequent executions of the script. Handling requesting binary resources within the containers was not part of our goals, and thus it simply outputs an error message.
Web Application
A web application (Tunink 2018b) was prototyped to provide a mechanism to browse the KDA repository on the web and then add views of 3D models to a collection on a page. To develop a prototype web application the Python “Bottle” web framework was selected. Bottle is easy to set up and has no non-Python dependencies, making it easy for prototyping and rapid development. The RDFLib script incorporated into the Bottle framework, along with the Bootstrap CSS framework to make the Fedora 3D Viewer interface mobile-friendly.
Figure Nine
Screenshot of Fedora viewer mockup
We developed the Fedora.py script to set up the fedora repository to run on the web (via the bottle webserver) and then sets up the variables necessary to store and index 3D mesh, texture (image) and metadata (json) files, including a basic parent/child hierarchy. To support calling up the 3D models, the fedora.py script identifies binary files in the repository by identifying resources within a container based on the file extension at the end of the resource identifier. It then stores them within a Python dictionary of model-related files. With this dictionary, we display files based on their purpose on the page: model files, texture files, metadata file, and CityEngine (cga) files. The Run.py starts the bottle webserver and calls fedora.py to load in the repository. This script effectively just pushes the 'go' button.
Fedora 3D Viewer: a Three.js application
Three 3D viewers were intially considered for this application: 3DHOP (Visual Computing Laboratory 2018a), ADS 3D Viewer, and three.js (three.js Community 2018a). We selected three.js for 3D Viewer development because it natively supports both OBJ and COLLADA. We tested the ingest of 3D procedural models into the ADS Viewer, and while it imports the procedurally-generated OBJs, the process is not streamlined and it does not support COLLADA. As for 3DHOP, it natively supports PLY, and while it is possible to edit the code to import OBJs and convert to PLY, this process adds complexity and requries translating the original data. Following the research and development of Workflow #1, we determined that to achieve the project goals, COLLADA is the required 3D file format. Below we provide requirements for loading COLLADA models and textures as well as recommended camera setup.
Requirements for loading COLLADA Models
A CORS security header (Access-Control-Allow-Origin "*") must be set to allow browsers to load data from any domain. While example loading scripts for COLLADA (DAE) models are available from three.js (three.js Community 2018c), the example code was redundant and conditionally executed the code for loading COLLADA files based on what was in the Fedora container. When the models were first loading, we were only seeing sporadically textured 3D objects. After closer examination of the example source code, we noticed that it wasn't manually applying textures to the model like the OBJ loader had done. When we skipped this code for COLLADA models, we discovered that the COLLADA loader applies textures internally while loading the models.
Requirements for Textures
Collada files with single and multiple textures have their textures loaded automatically in the prototype system from Fedora to the viewer.
OBJ files with multiple textures require the use of the MTL loader, which has not been implemented at this stage of the project.
The three.js documentation contains a list of supported formats (three.js Community 2018f). It should be noted for end users that .tif, exported by CityEngine, is not compatible at this time.
Recommended Camera Setup & Controls
Using a fixed grid and COLLADA orbital camera controls (three.js Community 2018d; three.js Community 2018e) provides a clean mode of interaction for both desktop and mobile touch devices. A brief descriptions of how to use the camera controls was added to the Fedora 3D viewer page.
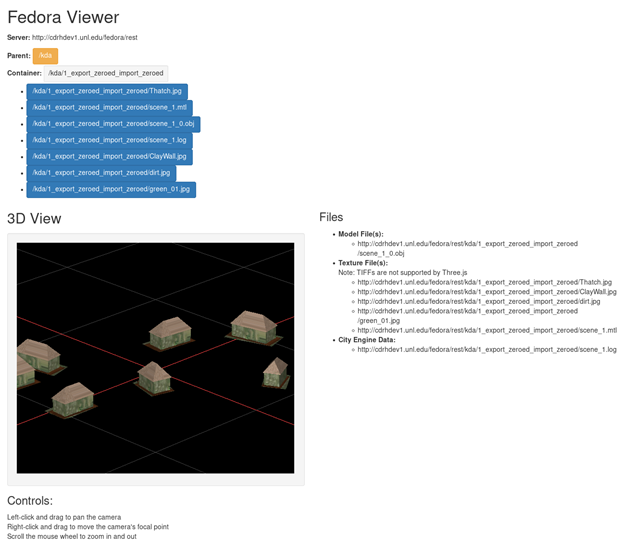
Figure Ten
Screenshot of Fedora viewer mockup
Importing (modified) Scenes from Fedora 3D Viewer into Repository
Workflow #3 defines requirements for how scene and model files are to be organized together for export to the Fedora 3D Viewer. While the read_fedora.py script currently does not zip the files, Python provides utilities to automate this step. These files could be zipped into a single archive file and be uploaded to the web application for ingest into the Fedora repository. The web application will then just need to unzip the files and post them to the Fedora API (DuraSpace 2018a).
When researching and developing Workflow #1 (CityEngine export organization), the possibility of creating a BagIt (IETF Network Working Group 2018) file was mentioned. There is already a Python library to work with BagIt files, so this may be able to simplify the file archival programming while also using a more interoperable storage format. Many other programming languages have BagIt libraries as well. BagIt archives also provide for metadata storage and file integrity verification with checksums. These are both features important to preserving 3D model data in transit.
GL Transmission Format
Three.js has its own recommended workflow for serving models to the web (three.js Community 2018h). This includes converting model files to another format, GL Transmission Format (glTF), for more efficient loading over the Internet. CityEngine does not support export to this format, but there are a wide variety of tools to convert different file formats to glTF's. This functionality may be added to the uploading or request handling process in the future to serve models from a production KDA repository.
Data Integrity with Fixity
Fedora will verify provided checksums upon ingest or generate its own (DuraSpace 2018b) if one is not provided. Fedora includes the Fixity tool to verify these checksums on-demand to verify the binary content via its REST API. Standard procedures for checking and maintaining data integrity for resources already ingested should be the subject of future development, based on methods implemented in similar Fedora repositories. Such procedures would likely include regular, automated integrity checks on all of the data and/or additional checks before serving files for download